


Interface編集部

連載・AIエージェント補足資料
本資料は,記事「OpenAI Agents SDKで始める自分専用AIエージェント開発」に関する補足情報をまとめたものです.本誌では,OpenAI Agents SDK使用したエージェント開発を安定して進めるための基盤となるOpenAI Platformについて,記事本文を補完する技術的な解説や追加情報を中心に整理します.
<<<<<連載第2回(2026年3月号)補足(2026.1.27)
本資料は第1回の記事を未読の読者でも理解できるように,第1回で解説した内容(Agents SDKおよびAIエージェント開発の全体像)の要点を簡潔にまとめています.記事本文と併せて参照することで,OpenAI Agents SDKの理解をより深め,自分専用のAIエージェントを実際に設計,拡張するための具体的な判断材料を得ることを目的としています.以下に次の項目を記します.
①AIエージェントの概要
②OpenAI Agents SDK
③OpenAI platform実運用ガイド
=======================
①AIエージェントの概要
=======================
AIエージェントとは,特定の目標を達成するために自律的に判断,行動し,外部環境や各種ツールと連携しながら処理を進めるシステムです.LLMを中核として以下の機能を含みます.
1.自律的な意思決定
2.外部環境との継続的な相互作用
3.外部ツールやAPIの実行
4.複数ステップにわたるタスク処理
5.目標に基づく計画立案と状態管理
従来のエージェント・システムでは,ルール設計,状態管理,学習アルゴリズムの実装などを開発者が個別に設計する必要があり,実装や運用のハードルは決して低くありませんでした.しかし,LLM(大規模言語モデル)の登場により,自然言語による柔軟な判断や推論を,AIエージェントの思考エンジンとして利用できるようになりました.比較的少ない実装量で高度なエージェントを構築できる環境が整いつつあります.
●LLMとの違い
LLMの動作はあくまでユーザからの逐次的な入力に依存しており,能動的に行動を継続する存在ではない点が重要な違いです.LLMは,自然言語を入力として受け取り,統計的推論に基づいてテキストを生成するモデルです.例えば,プロンプトで「あなたは金融システム開発のスペシャリストです」と指示すると,あたかも1体のエージェントが生成されたかのように感じられます.しかし,実際に変化しているのは,応答のトーンや語調,文体といった表層的な振る舞いに過ぎません.LLMの動作はあくまでユーザからの逐次的な入力に依存しており,能動的に行動を継続する存在ではない点が,AIエージェントとの大きな違いです.
●エージェントの理論モデル(三層構成)
エージェントの基本構造は,三層構成モデルとして整理されることが多く,これはロボティクスや知能システム分野で古くから用いられてきた設計思想です.
1.認知層(Perception)
外部環境を観測し,必要な情報を取得・前処理する層です.
2.計画層(Planning)
取得した情報と設定された目標に基づき,行動方針や手順を決定する層です.
3.実行層(Action)
計画に従って外部環境に働きかけ,実際の行動を実行する層です.この三層構成により,各機能を明確に分離できるため,モジュールの交換や拡張が容易になります.また,認知・計画・実行を独立して改良できるため,異なるアプリケーション間での再利用性も高まります.
●AIエージェントの実装アーキテクチャ(レイヤ構成)
近年のAIエージェントでは,前述の三層構成モデルをそのまま実装するのではなく,実装上の責務に応じたレイヤ分離が行われるケースが一般的です.理論モデルと実装モデルを対応付けて理解しておくことで,設計段階から実装段階まで一貫した思考が可能になります.以下に代表的な対応関係を示します.

このように対応関係を明確にしておくことで,理論的なエージェント設計とLLMエージェント実装を無理なく接続でき,設計漏れや責務の混在を防ぎやすくなります.
●AIエージェント開発の課題
AIエージェントをゼロから構築しようとすると,単にLLMを呼び出すだけでは済まない,複合的な技術要素を考慮する必要があります.代表的な課題を以下に示します.
1.LLMの選定とプロンプト設計
用途に応じたモデル選択や,安定した推論結果を得るためのプロンプト設計が必要です.
2.タスク分解と処理フロー制御
曖昧な指示を複数の処理ステップに分解し,適切な順序で実行する仕組みが求められます.
3.外部ツール・APIとの連携
ファイル操作やWeb API呼び出しなど,LLM単体では実行できない処理を安全に統合する必要があります.
4.状態管理やメモリ管理
会話履歴や中間結果をどのように保持し,どこまで参照させるかといった設計が重要です.
5.非同期処理およびエラー対応
外部ツールの失敗やタイムアウトに備えた制御が不可欠です.
6.安全性・信頼性の確保
不正入力や想定外の指示に対する制限,実行可能な操作範囲の管理が求められます.
これらの要素をすべて個別に設計・実装・検証するのは容易ではありません.特に,業務用途や製品レベルでの利用を想定した場合,実装コストだけでなく,保守や拡張にかかる負担も大きくなります.このような背景から,エージェント開発に必要な共通機能をフレームワークとして提供する仕組みが求められています.
●AIエージェント開発の負担を軽減するSDKやフレームワーク
代表的なものとして,OpenAI Agents SDK をはじめ,LangGraph,AutoGen,CrewAI,MetaGPT などが挙げられます.これらのSDKやフレームワークは,LLMとの連携,状態管理,処理フロー制御などをモジュール化しており,ゼロから実装する場合と比べて大幅に工数を削減できます.これらはそれぞれ異なる設計思想とアプローチを採用しており,用途や開発体制によって適・不適が分かれます.
以下は,筆者の使用経験に基づき,OpenAI Agents SDKと主要なSDKを比較したものです.なお,本比較には実務上の主観的評価が含まれるため,最終的な選定は目的や開発環境に応じて判断してください.

中でも特に注目すべきなのは,OpenAI Agents SDKがセーフティ制御(Guardrails機能)を初期状態で統合している点です.これにより,追加実装なしで次のようなセーフガードを実現できます.
・入力検証:形式や内容の妥当性チェック
・出力制御:不適切または危険な内容の抑止
・実行防止:意図しないAPI呼び出しや不正コマンドの実行防止
これらの機能により,セキュリティや信頼性が求められる商用システムやPoC(概念実証)開発でも,安全かつ迅速に導入できる点は,本SDKならではの大きな強みです.
本資料では,これらの中でも筆者が特に注目しているOpenAI Agents SDKについて次で詳しく解説します.
=======================
②OpenAI Agents SDK
=======================
OpenAI Agents SDKは,OpenAIが提供するオープンソースの開発フレームワークです.
LLMを中核としたエージェント型アプリケーションを,効率的かつ柔軟に開発できるよう設計されており,十分に役立つ機能を備えつつ,学習コストが増えない範囲に「基本構成要素」を絞り込む設計方針を採っています.また,実装言語としてはPython版に加えてTypeScript版も提供されており,バックエンド/フロントエンドを含む幅広い開発環境で採用しやすくなっています.
この設計方針に基づき,エージェント開発に必要となる主要な概念と機能が,あらかじめ整理された「基本構成要素」として提供されています.主な構成要素は次のとおりです.
・Agent(エージェント)
指示(instruction)とツール(tools)を組み合わせ,LLMが自律的にタスクを実行するための基本ユニットです.エージェントの振る舞いや役割は,この単位で定義します.
・Handoff(ハンドオフ)
処理を別のエージェントへ委譲する仕組みです.複数エージェントによるタスク分担や段階的な処理を実現でき,役割分離されたエージェント設計を可能にします.
・Guardrails(ガードレール)
入力の検証や動作の制限を行い,エージェントの信頼性と安全性を確保する制御機構です.不正な入力の拒否や,想定外のAPI呼び出しの抑止などを,追加実装なしで組み込めます.
・Session(セッション)
会話履歴や状態情報をエージェント実行間で自動的に保持する仕組みです.これにより,文脈を維持した対話や,複数ステップにわたるタスク処理が容易になります.これらの機能はすべてPythonコードで記述・制御でき,単一のシンプルなエージェント構成から,複数エージェントを連携させた複雑なワークフローまで柔軟に対応できます.特に,Agents SDKはエージェント実行のトレース取得(トレーシング)に標準対応しており,実行の流れを追跡しやすい点が特長です.取得したトレースはOpenAI Platformのダッシュボードで可視化できるため,デバッグや挙動の検証を効率化できます.
●必要な環境
OpenAI Agents SDK(Python版)はGitHubでソースコードが公開されており,PyPIからもインストール可能です.リポジトリは以下から入手できます.
https://github.com/openai/openai-agents-python
●サインアップと API Key取得の流れ
OpenAI Agents SDKのサンプルコードやデモを実行するには,環境変数 OPENAI_API_KEY にOpenAI APIのシークレットキーを設定する必要があります.そのため,事前にOpenAI Platformへサインアップし,プロジェクトを作成したうえでAPIキーを発行します.取得したAPIキーは,各開発環境に応じて環境変数として設定してください.
―――――――――――――――――――
OpenAI API公式サイト
( https://openai.com/ja-JP/index/openai-api/)
――――――――――――――――――
=======================
③OpenAI platform実運用ガイド
=======================
誌面では,OpenAI Platformを「Agents SDK開発の管理ツール」として,API Keys,Billing,Limits,Usage,Logs,Tracesの確認手順を中心に紹介しました.一方,読者が実際に運用を始めると,次の段階で必ず詰まります.
・開発/本番のProject分離をどう作るか
・APIキーを誰が・どの権限で持つべきか
・Usageが見えない(権限・可視性設定)など,権限周りの落とし穴
・ログやトレースを扱うなら避けられないデータ保持(store/ZDR)
・大量実行で429に詰まったときのSync / Batchの使い分け
本稿では,「最初に知っておくと手戻りが減る」項目を,実装方針に落とし込める形で整理します.
●Project運用:dev/prod分離とメンバ管理
▲Projectを分けると何が嬉しいか
・dev:試行錯誤(ログも多い/キーも増える)
・prod:最小権限・監査・予算管理
この分離は,後からやるほど移行コストが上がります.
▲画面操作:Projectにメンバを追加する
1.右上の Settings(歯車)を開きます(誌面の導線と同じ).
2.Organization settingsを開き,対象Projectを選びます.
3.Members を開き,+ Add member をクリックします.
4.追加するユーザを選び,Role(Member / Owner)を指定します.
▲Roleの使い分け(最低限)
・Owner:Project設定・予算・制限・メンバ管理まで触れます
・Member:通常の開発者はここで足ります(Ownerを増やしすぎないのがコツ)
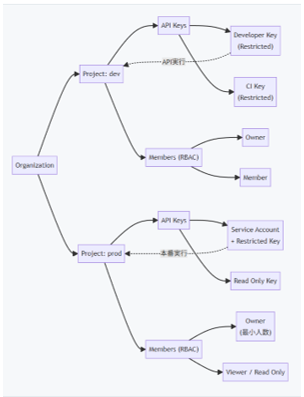
●“人ではない実行主体”:Service Accountで運用を安定させる
▲なぜService Accountが必要か
CI/CDや常駐デモ,社内PoCで個人のAPIキーを使うと,異動や退職,端末更新で止まります.Service Accountは「システム用の疑似ユーザ」で,Projectスコープで運用できます.
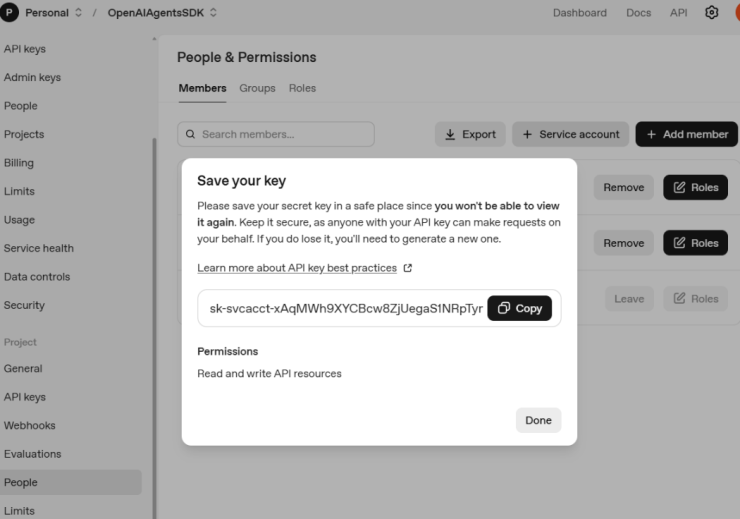
▲画面操作:Service Accountを作成する
・作成手順
1.まず 対象Projectに切り替えます(1章の手順).
2.Settings(歯車)→ Organization settings を開きます.
3.左のナビで対象Projectを選び,Propleを開きます.
4.+ Service account をクリックします.
5.作成するとAPIキー(Secret key)が一度だけ表示されるので,必ず安全な場所に保存します.
※:https://help.openai.com/en/articles/9186755-managing-projects-in-the-api-platform
●Projectの制限:予算(Budget)とModel Usageを“画面で”締める
▲Limitsは「レート」だけではありません
誌面でもLimits画面(レート・モデル別制限・上限金額)を紹介しましたが,別冊では「Project側でどこまで締められるか」を補足します.
▲画面操作:Project Limits(予算・Model Usage)を設定する
4.2.1. Project側のLimits
1.Settings(歯車)→ Organization settings を開きます.
2.対象Projectを選択します.
3.Projectセクションにある Limits を開きます.
4.Monthly budget や Add alertを設定します.
●RBAC:大人数運用の現実解(見えるUIが違う点に注意)
▲RBACの要点
RBAC(Role-based access control)は「誰が何をできるか」を,DashboardとAPIの両方に一貫して効かせる仕組みです. なお,RBACは段階的提供で,組織によってはUIに出ない場合があります.
▲画面操作:RBAC(見える場合)の典型導線
まずやること(小規模チームでも効く)
1.Organization settings を開きます.
2.Roles / Groups(またはPermissions関連)を探します(RBACが有効な組織のみ表示されます).
3.“最小権限”でカスタムRoleを作り,必要なユーザ/グループに割り当てます.
※:実務メモ:
「全員Owner」は短期的に楽ですが,ログ閲覧・キー作成・予算変更が無制限になり,運用事故の温床になります.
※:https://platform.openai.com/docs/guides/rbac
●可観測性:Logs / Traces を“使える状態”にする
▲Tracesの基本導線(誌面のおさらい+補足)
Tracesは,Agents SDKなどのワークフロー実行を追跡でき,Dashboardの Logs > Traces で確認します.
また誌面にもある通り,Agents SDK経由で実行していないとTracesが出ません.
▲画面操作:Tracesを開く(Traces確認手順)
1.左メニュー(または上部ナビ)から Logs を開きます.
2.Traces を選択します.
3.対象ワークフロー/対象traceを選び,ステップを展開して確認します.
● Usageが見えない問題:原因は「Project権限」ではない場合があります
▲なぜ見えないのか
Helpでは「ProjectのUsage Dashboard可視性は,Project内ロールではなくOrganization側の設定で決まる」と説明されています.
つまり,ProjectのMember/Owner設定だけを見直しても解決しない場合があります.
▲画面操作:Usage Dashboard可視性の確認
1.Settings(歯車)→ Organization settings を開きます.
2.Data controls(可視性設定)を探し,Usage Dashboardの表示範囲(例:Ownersのみ等)を確認します.
●データ保持とZDRの基本を押さえる
参考サイト:https://platform.openai.com/docs/guides/your-data?utm_source=chatgpt.com
▲Platformに保存されるデータの種類
OpenAI Platformのデータ取り扱いは,大きくAbuse monitoring logsとApplication stateに整理されています.
▲Responsesのstoreと既定保持
Responses APIは,既定(またはstore=true)でアプリケーション状態が一定期間保持される旨が説明されています.ドキュメントでは少なくとも30日保持される,と整理されています.
▲Zero Data Retention(ZDR)の影響
ZDRが有効な組織では,storeは常にfalse扱いになり,保存を要求しても保存されません. また,機能によってはZDRと相性が悪い場合があり,例えばbackground modeではポーリングのために短時間保持が発生し得るため,ZDR要件があるなら避けるべき,と注意されています.
▲原稿での安全な書き方
・「保存される/されない」はstoreとZDRで決まります.
・ZDR前提だと,状態保持をアプリ側で設計する必要が出ます(会話状態や復元手段など).
●Sync vs Batch:429に詰まったら設計を分ける
▲判断基準は「待てるかどうか」です
同期(Sync)は対話やUIに必要です.一方,評価・回帰テスト・データ生成など「待てる処理」はBatchへ逃がすと,低コスト・高いレート枠,24時間ターンアラウンドという利点が得られます.
▲画面操作:Batches(UIが提供されている場合)
BatchはAPI中心で使えますが,Dashboard側に Batchesページがある構成も報告されています.UIが見える場合は,次の用途で便利です.
・投入したバッチの進捗確認
・成功/失敗件数の確認
・出力ファイルの扱い確認(APIと合わせて)
注意:Batchesメニューの有無や位置はアカウント/時期で変わる可能性があります(UIがない場合はAPIのみで運用します).
▲Batch APIの特徴(補足)
Batch APIは,同期APIに比べてコスト割引,より高いレート上限,24時間以内の完了が特徴として整理されています.同期で回すとレート制限とコストの両面で苦しくなるため,Batchに逃がす設計は効果が大きいです.
●付録:読者向けチェックリスト
本資料で紹介した構成を実際のシステムに適用する際,最低限確認しておきたい項目を以下にまとめます.検証用途,試作段階であっても,将来の運用を見据えて一度は確認しておくことを推奨します.
•dev/prodでProjectを分けましたか
•キーに権限(Restricted/Read Only)を付けましたか
•常駐処理はService Accountを使いましたか
•Audit Logsを有効化し,無効化できない点を理解しましたか
•store/ZDRの挙動を理解しましたか
•429対策(指数バックオフ)を入れましたか
•大量処理はBatchへ逃がす設計にしましたか
•Usage/Costs APIでコスト集計の道筋を作りましたか
<<<<<








ショップへのリンク")

