


Interface編集部

2023年4月号 特集3 第2部 第2章 学習済みモデルを利用した半自動アノテーション サポート・ページ
筆者提供のGoogleColaboratoryのノートブック
https://colab.research.google.com/drive/1dHo9BEGuFF-LFcqyEU-6GDswWimXTR4y?usp=sharing
chromeブラウザを推奨します.
●記事中の図
DAVIS:Densely Annotated VIdeo Segmentation.(https://davischallenge.org)の図を引用

図1 DAVISデータセットの可視化
この動画には5クラスの領域が与えられているので,各領域を対応する色で塗りつぶしている

図2 左の人物の領域から抽出した特徴ベクトルと類似する領域
右の人物の領域も抽出されている

図3 正例(左の人物)と負例(それ以外)の比較で得られた領域

(a)転移元画像(上端)と転移先画像(左端)の特徴ベクトルの組み合わせについて方向余弦を求める
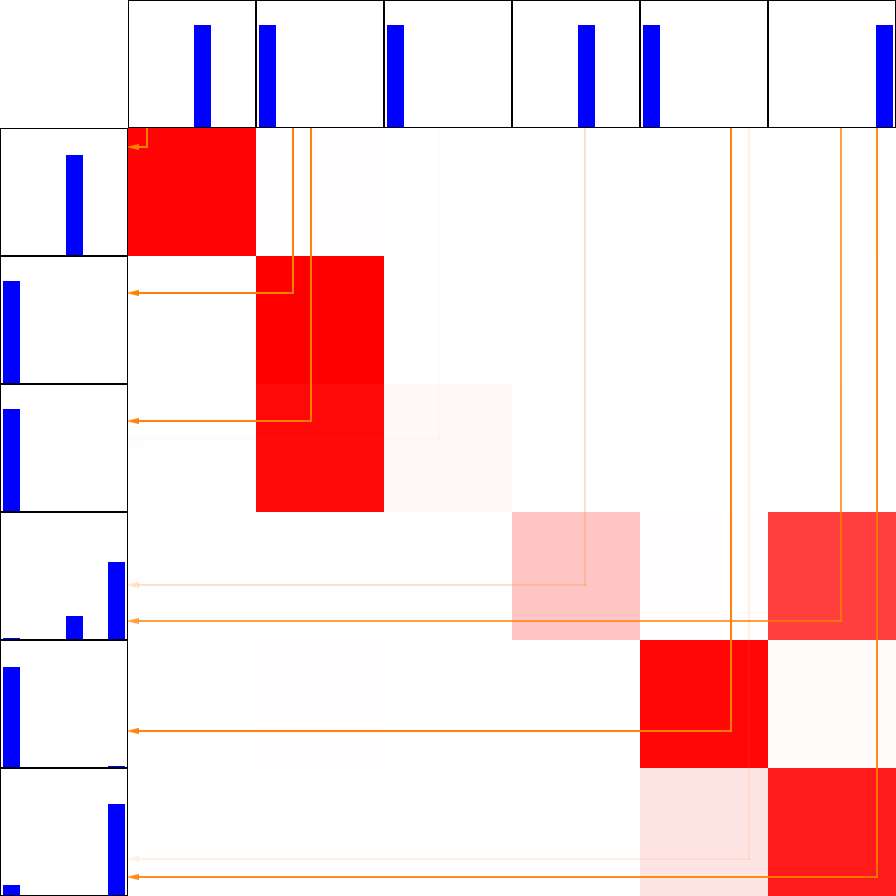
(b)方向余弦のsoftmaxに基づいて,矢印のように転移元(上端)から転移先(左端)へラベルを転移
図4 特徴量に基づくラベル転移

図5 ラベルの転移によって得られた2クラスの領域

図6 推定された領域のバウンディング・ボックス
単に外接矩形を計算すると,推定が間違っている少数の領域の影響を受けて,期待するものと大きく異な
るものが得られる

図7 ランダムにサンプリングしたバウンディング・ボックス

図8 推定された領域とのIoUが0.5以上となるバウンディング・ボックス

図9 選択したサンプルから構成したバウンディング・ボックス

図10 画像1

図11 画像2
画像1から10フレーム先の画像を左右反転したもの

図12 画像1のラベルを図示したもの
実際は各バウンディング・ボックスについて,その内部が1,外部が0となっている2次元マップが対応しているが,色分けして塗りつぶすことで可視化している.バウンディング・ボックスが重なり合う部分では色を加算しているため,一部で色使いに重複がある

図13 特徴量による類似度に基づいて画像1のラベルを画像2に転移
これらを画像2のバウンディング・ボックスと比較する
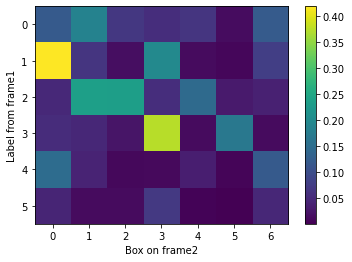
図14 画像1から画像2に転移した各領域(縦軸)と画像2の各領域(横軸)について計算したIoU








ショップへのリンク")