


Interface編集部

ailia SDKを試す<第7回> Qwen-Audioで音声認識
今回は,ailia-SDKを用いた音声認識の実装方法について紹介します.音声認識には,ailia-models に含まれるqwen_audioを利用します.これは,Qwen-Audio(Qwen Large Audio Language Model)をailia-SDK上で動作可能にしたものです.
●Qwen-Audioの特長
Qwen-Audioは,Alibaba Cloudが開発する大規模モデル・シリーズQwen(通義千問/Tongyi Qianwen)のマルチモーダル版に位置づけられます.人間の音声だけでなく,自然音や音楽,歌声など多様な音声を入力として扱うことができ,与えられたプロンプトに基づいて内容を判定し,テキストとして出力する機能を備えています.単なる文字起こしにとどまらず,「これは何か?」,「どんな内容か?」といった意味的な問いかけにも対応できる点が特長です.
●実行環境
今回使用した環境を表1に示します.
| 名称 | 内容 |
|---|---|
| OS | Windows 11 Pro |
| CPU | インテル® Core™ i5-10500 |
| RAM | 128GB |
| GPU | NVIDIA GeForce RTX-5060 Ti 16GB |
| Python | python-3.10.11-amd64 |
| ailia-SDK | Version 1.5.0.0 |
| ailia-models | v1.4.0 https://github.com/axinc-ai/ailia-models |
表1 システム構成一覧
なお,メモリは32GB程度の環境でも実行可能ですが,処理時間がかなり長くなるため,出来れば64GB以上を推奨します.
●環境構築してQwen-Audioを動かしてみる
まずは環境の構築手順をリスト1に示します.
******
> python –version
Python 3.10.11 <―― Python のバージョンは、3.10以下にしてください
> git clone https://github.com/axinc-ai/ailia-models.git
> cd ailia-models
> python -m venv .venv <―― Pythonの仮想環境 作成
> .venv\Scripts\activate <―― 仮想環境 で作業してください
> python -m pip install –upgrade pip
> pip install setuptools wheel
# matplotlib、scikit-image、pillow に関しては依存するバージョンがあります
> pip install matplotlib==3.8
> pip install “scikit-image<0.20” “pillow<10”
> pip install -r requirements.txt
#Qwen-Audio用の追加モジュール
> pip3 install transformers
> pip3 install tiktoken
> pip3 install librosa
******
リスト1 環境構築の手順
次にリスト2のようにQwen-Audioを実行します.
******
(.venv) PS ailia-models\audio_language_model\qwen_audio> python .\qwen_audio.py
INFO arg_utils.py (13) : Start!
INFO arg_utils.py (163) : env_id: 1
INFO arg_utils.py (166) : CPU-IntelMKL
INFO model_utils.py (74) : Downloading onnx file… (save path: Qwen-Audio-Chat.onnx)
INFO model_utils.py (80) : ======================= 100.00% ( 2011KB )]
INFO model_utils.py (82) : Downloading prototxt file… (save path: Qwen-Audio-Chat.onnx.prototxt)
INFO model_utils.py (88) : ======================= 100.00% ( 3012KB )]
INFO model_utils.py (89) : ONNX file and Prototxt file are prepared!
INFO model_utils.py (74) : Downloading onnx file… (save path: Qwen-Audio-Chat_encode.onnx)
INFO model_utils.py (80) : ======================= 100.00% ( 1267006KB )]
INFO model_utils.py (82) : Downloading prototxt file… (save path: Qwen-Audio-Chat_encode.onnx.prototxt)
INFO model_utils.py (88) : ======================= 100.00% ( 10987KB )]
INFO model_utils.py (89) : ONNX file and Prototxt file are prepared!
INFO model_utils.py (107) : Downloading Qwen-Audio-Chat_weights.pb…
INFO model_utils.py (109) : Qwen-Audio-Chat_weights.pb is prepared!88KB )]
INFO license.py (122) : Download license file for ailia SDK.
INFO license.py (81) : ailiaへようこそ。ailia SDKは商用ライブラリです。特定の条件下では、無償使用いただけますが、原則として有償ソフトウェアです。詳細は https://ailia.ai/license/ を参照してください。
audio_start_id: 155163, audio_end_id: 155164, audio_pad_id: 151851.
INFO qwen_audio.py (520) : Prompt: what does the person say?
INFO qwen_audio.py (528) : Start inference…
The person says: “mister quilter is the apostle of the middle classes and we are glad to welcome his gospel”.
INFO qwen_audio.py (556) : Script finished successfully.
(.venv) PS ailia-models\audio_language_model\qwen_audio>
******
リスト2 ailia SDK上でQwen-Audioを実行
今回の環境では,GPUが認識されずCPU-IntelMKL(env_id=1)で実行しています.
なお,–env_idオプションを使用して GPU(VulkanDNN)を明示的に指定した場合,モデルの初期化までは正常に完了し,推論処理も一部は実行されました.しかし,途中の処理段階でエラーが発生し,最後まで処理を完了することはできませんでした.
このようなケースでは,次の点に注意が必要です.
******
・GPUドライバやVulkanランタイムのバージョンに依存して動作が不安定になる場合がある.
・入力する音声が長尺である,またはメモリ使用量が多くなる条件下では,Vulkan実行時にクラッシュやメモリ・エラーが発生する可能性がある.
・安定性を重視する場合は,まずenv_id=1(CPU-IntelMKL)を使用し,GPU実行は環境を整えたうえで段階的に試す.
******
最後に実行結果を見てみます.今回使用したサンプル音声を処理したところ,次の出力が得られました.
******
The person says: “mister quilter is the apostle of the middle classes and we are glad to welcome his gospel”.
******
この出力は,ailia-modelsの公式リポジトリ(README.md)に記載されているサンプル結果と完全に一致しており,正しく音声を認識/処理できていることが確認できました.これにより,環境構築とモデルの推論が問題なく動作していることが実証されました.初期動作確認としては十分な結果です.
●さまざまなデータで認識精度を検証
先に構築した環境で他の音声やプロンプトを用いた検証をすることします.
▲検証1…単語の発話
別の音声データを用いた検証を行いました.また,検証に使用したプロンプトは,日本語で「これはなに?」としました.通常の文字起こしでは,音声内容をそのままテキスト化しますが,ここでは 「これはなに?」と問うことで,入力音声の意味を解釈するモードとして動作を検証します.使用した音声データは,Qwen-Audioの公式リポジトリに含まれるサンプルから取得しました.
データ入手先は次のQwen-Audio GitHubリポジトリから取得しました.
******
https://github.com/QwenLM/Qwen-Audio/blob/main/assets/audio」
******
データ・ファイル1089_134686_000007_000004_companionless.wav(内容は単語companionlessの発話)を用いた結果,次の結果が得られました.
******
(.venv) PS> python.exe qwen_audio.py –input 1089_134686_000007_000004_companionless.wav –prompt “これはなに?”
:
これは、「伴侣なし」の意味です。
******
このように,入力された音声を単に英単語として認識するだけでなく,「これはなに?」というプロンプトに応じて,その意味を日本語で説明する形式で返していることが分かります.
▲検証2…英語の詩
次にデータ・ファイル1089_134686_000007_000004.wavを使用します.内容は,「the music came nearer and he recalled the words the words of shelley’s fragment upon the moon wandering companionless pale for weariness」シェリーの詩の断片です.
Qwen-Audiの実行後,次の結果となりました.
******
(.venv) PS> python.exe qwen_audio.py –input 1089_134686_000007_000004.wav –prompt “これはなに?”
:
これは文章です。文章は、ある男性が音楽が近づいて、彼は彼の過去に回顧するようになります。彼は音楽に聴き入るようになり、彼の心に響く歌が聞こえてくるようになります。その歌は、シッキーズの歌です。その歌は、彼の心に深く響くようになります。彼は、その歌が彼の心に響くことを感じ、彼はその歌を歌い始めます。彼は歌い始めると、彼の心は歌の世界に浸り、彼は歌に聴き入ります。
******
入力音声は,シェリーの詩の一節を含む英文であり,詩的かつ抽象的な表現を含んでいます.出力では「音楽が心に響き,男性が過去を回想する」というような,詩的イメージを意訳したような解釈が提示されました.もちろん,細部の表現や登場する単語は原文と異なる部分もありますが,「これはなに?」という問いに対して,単語や文章を逐語的に認識するのではなく,文全体の情景や感情的ニュアンスをくみ取ろうとしている様子がうかがえます.
従って,出力内容は完全な翻訳ではないものの,文脈や意味の解釈を試みた結果としては十分に意図に沿ったものと評価できます.
▲検証3…ガラスの割れる音
データ・ファイルglass-breaking-151256.mp3(内容はガラスが割れる音)を使用したら,次の結果が得られました.
******
(.venv) PS > python.exe qwen_audio.py –input glass-breaking-151256.mp3 –prompt “これはなに?”
:
これは、コンピューターゲームの音楽です。
******
実際にはガラスの割れる音であるにもかかわらず,出力ではコンピュータ・ゲームの音楽と誤認されました.おそらく,ゲーム内で使用される効果音のように聞こえたため,音楽的なカテゴリに分類されたと考えられます.この結果から分かるのは,Qwen-Audioが言語的/意味的な情報に対しては高度な解釈を行える一方で,非言語的な自然音や環境音の分類については,誤認の可能性があるということです.
なお,「これはなに?」というプロンプトに対しては,音の意味や用途を推測して回答しようとする傾向になるため,分類結果が必ずしも音源そのものの正確なラベルと一致するとは限りません.
▲検証4…ナレーションに似た気象情報の読み上げ
データ・ファイルvoicevox1.wav(VOICEVOX「四国めたん(ノーマル)」で生成,内容は気象情報の読み上げ)を使用します.音声の内容は,四国地方の気象情報を読み上げたニュース風のナレーションです.具体的には,
******
四国地方では、四日昼ごろから五日にかけて全般で雨となり、太平洋側を中心に、局地的に雷を伴って非常に激しくおり、大雨となる恐れがあります。
******
といった内容です.
このデータを利用したら,次のような認識結果となりました.
******
(.venv) PS > python.exe qwen_audio.py –input voicevox1.wav –prompt “これはなに?”
:
これは日本語の歌です。歌詞は「四国地方では、四日昼ごろから五日にかけて前半に雨となり、太平洋側を中心に、局地的に雷を伴って非常に激しくおり、大雨となる恐れがあります。」です。
******
実際の入力はニュース風の読み上げ音声ですが,結果では日本語の歌と認識されました(図1).
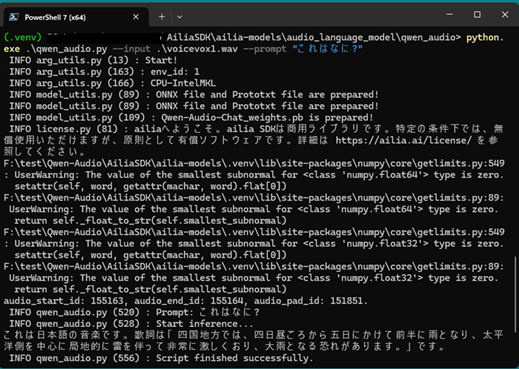
図1 Qwen-Audioを利用した認識結果の例
これは,VOICEVOXの特徴的な抑揚や流れるような発声が,歌唱に近いものと判断されたためと考えられます.また,文字変換の細部では「全般(ぜんぱん)」が「前半(ぜんはん)」と誤変換されるなど,音声認識精度の課題も見られました.この検証から,Qwen-Audioは音声の種類(読み上げか歌か)を解釈する能力を持つ一方で,合成音声特有のイントネーションに影響を受けやすいことが確認できます.
▲Qwen-Audioの精度を整理
ailia-SDK上でQwen-Audioを実行し,複数の音声データを用いて挙動を検証した結果を整理すると次の特徴が見えてきます.
******
・単語レベルの音声:単なる文字起こしに留まらず,意味を日本語に翻訳して返答できる.
・文章レベルの音声:音声の内容を解釈し,文脈に沿った説明を返すことが確認できる.細部は異なるものの,意味理解に基づいた出力が得られた.
・自然音(非言語音):ガラスの割れる音をゲーム音楽と誤認するなど,非言語音の分類には誤判定の可能性がある.
・合成音声:読み上げ音声を歌と誤認する例がある.これは合成音声特有の抑揚やリズムに影響を受けた結果と考えられる.
******
●まとめ
Qwen-Audioは,音声を単にテキスト化するだけでなく,与えられたプロンプトに応じて意味解釈や内容説明まで行うことができる点が大きな特徴です.特に,「これはなに?」,「どういう内容か?」といった意味的な問いかけに対して,入力音声を解釈し,文脈に沿った回答を生成できることは,従来の音声認識モデルとは一線を画しています.
一方で,自然音や合成音声といった言語に依存しない曖昧な音声に対しては,誤認が発生するケースもあり,入力音声の種類によっては注意が必要です.そのためQwen-Audioをより実用的に活用するためには,入力音声の種類とプロンプトとの関係性を理解したうえで設計することが重要です.今後,音声アシスタントや学習支援,マルチモーダルなユーザ・インターフェースといった分野では,Qwen-Audioのようなモデルの特徴を活かした応用がますます広がっていくと考えられます.
氏森 充(うじもり・たかし)
約30年間,(株)構造計画研究所にてIoT,ビッグデータ,機械学習,AI関連のシステム開発や実務応用に従事.退職後はLLM(大規模言語モデル)関連の情報収集や技術動向の調査・発信に注力し,雑誌「Interface」でもLLM技術に関する記事を執筆中.








ショップへのリンク")

