


Interface編集部
ailia SDKを試す<第12回> places365で動画のシーン推定
今回は画像からビーチや書斎,公園といったシーン・カテゴリを推定できるPlaces365系(注1)モデルを,ailia SDKのサンプル・プログラム(places365.py)を用いて,動画入力に対する場所推定を検証します.前回(https://interface.cqpub.co.jp/ailia011/)は静止画を対象とした検証を紹介しましたが,今回はその続編として,前回扱えなかった 動画入力での推定を検証します.
なお,環境構築手順や使用モデルの概要については前回記事を参照してください.今回は特に,動画処理における推定時間の計測や,ResNet-18/WideResNet-18モデルを用いた精度と速度の比較に焦点を当てます.これにより,両モデルの特性やトレードオフを手元の環境で実際に確認できることを狙いとしています.
ーーーー
注1:Places365:https://github.com/CSAILVision/places365
●検証環境や条件
▲使用するシーン
検証に使用した動画は,ailia-models\landmark_classification\places365に付属する庭(patio)の画像と,前回の検証で使用した静止画5枚を組み合わせて作成しました.具体的に使用したシーンは次の通りです.
******
・庭(patio)
・地下鉄のホーム
・オフィス
・公園(Formal garden)
・芝生の上を歩く猫
******
各画像を4秒間表示させ,合計20秒の動画としました.編集にはMicrosoft Clipchampを使っています.
▲動画ファイルの仕様
作成した動画ファイルの仕様は次の通りです(画面サイズは大小2種類を用意しました).
******
・フォーマット:MP4
・フレーム・レート:30fps
・画面サイズ:640×480,960×720
******
▲検証項目
今回の検証では,次の3点を確認しました.
******
・GPUを利用した場合の効果
・画面サイズの違いによる処理速度の変化
・静止画推定と動画推定における結果の違い
******
今回使用した動画は,静止画を単純に連結したものに過ぎないため,各シーン内での画像変化はありません.ただし,本検証の目的は,動画化による推定処理時間の計測であるため,この構成で十分と考えています.
●スクリプトの実行方法
▲コマンド例
コマンド例を次に示します.
******
# (参考)WideResNet-18で動画をGPUで推定
PS> python places365.py –video test_20_760.mp4 –model wideresnet18 –env_id 2
# (参考)ResNet-18で動画をCPUで推定
PS> python places365.py –video test_20_760.mp4 –model resnet18 –env_id 0
******
動画ファイルの指定,使用するモデルの選択,さらに実行環境(CPU/GPU)は引数で指定できます.
******
・–video : 入力する動画ファイルを指定
・–model : 使用するモデル(resnet18またはwideresnet18)を指定
・–env_id : 実行環境を指定(0=CPU,1=CPU-MKL,2=GPU-FP32,3=GPU-FP16)
******
▲スクリプト修正点(計測の追加)
動画入力の推測処理に時間計測処理を追加しました.これにより,動画全体の処理時間やフレーム数から平均処理速度(FPS)を算出できます.次に追記した疑似コードの例を示します.
******
def recognize_from_video(net, weight, classes, labels_IO, labels_attribute, W_attribute):
capture = webcamera_utils.get_capture(args.video)
import time
start = time.perf_counter() #計測開始
locate0=””
while (True):
ret, frame = capture.read() # 動画から静止画を取得
img = apply_centre_crop(np.array(frame)) # リサイズ
#動画画像の推定処理
:
#同じ画像(フレーム)ならば、出力はしない。
if locate0 != classes[idx[0]] :
locate0 = classes[idx[0]]
print(locate0)
else:
continue
#動画画像の推定結果出力
end = time.perf_counter() #計測終了
print(‘{:.2f}sec , Frames = {}’.format((end-start),frame_i)) # 87.97(秒→分に直し)
******
リスト1 追加したコード
●動画を入力して検証開始
▲1,モデル:resnet18,画面サイズ:640×480
結果を表1に示します.
| 試験画像(画面サイズ) | 静止画 | 動画 |
|---|---|---|
| 庭(patio) 640×426 |
0.621→patio 0.310→restaurant_patio 0.020→beer_garden 0.011→courtyard 0.011→porch |
0.937→patio 0.035→restaurant_patio 0.006→beer_garden 0.006→courtyard 0.005→porch |
| 地下鉄のホーム 1536×1024 |
0.893→subway_station/platform 0.106→train_station/platform 0.000→arcade 0.000→railroad_track 0.000→corridor |
0.917→subway_station/platform 0.079→train_station/platform 0.001→arcade 0.001→corridor 0.000→airport_terminal |
| オフィス 1536×1024 |
0.244→office_cubicles 0.190→computer_room 0.141→office 0.135→library/indoor 0.120→classroom |
0.368→computer_room 0.221→library/indoor 0.108→office_cubicles 0.078→classroom 0.075→lecture_room |
| 公園(Formalgarden) 1536×1024 |
0.231→botanical_garden 0.224→park 0.211→formal_garden 0.084→orchard 0.077→field/wild |
0.813→formal_garden 0.047→vegetable_garden 0.032→botanical_garden 0.030→topiary_garden 0.019→roof_garden |
| 芝生の上を歩く猫 1536×1024 |
0.338→field_road 0.271→lawn 0.181→rice_paddy 0.066→pasture 0.047→hayfield |
0.424→lawn 0.177→field_road 0.089→rice_paddy 0.054→pasture 0.030→aquarium |
表1 試験データと結果(静止画 vs. 動画)1
結果を考察してみます.
******
・差が顕著だったシーン:オフィス,公園,芝生の猫で大きな違いが確認された.特に公園(formal garden)は,静止画では上位クラスが分散していたのに対し,動画ではformal_gardenが0.813と明確に優勢になった.
・画像サイズの影響:静止画(1536×1024)を640×480に縮小して再推定したところ,次の結果となった.
0.874 -> formal_garden
0.088 -> topiary_garden
0.013 -> botanical_garden
0.008 -> roof_garden
0.007 -> vegetable_garden
******
これは動画での推定結果と近い分布であり,入力画像のサイズや縦横比が前処理(リサイズ/クロップ)の挙動を変え,推定分布に大きく影響していることがわかりました.
▲2,モデル:wideresnet18,画面サイズ:640×480
結果を表2に示します.
| 試験画像(画面サイズ) | 静止画 | 動画 |
|---|---|---|
| 庭(patio) (640×426) |
0.651→patio 0.068→restaurant_patio 0.043→porch 0.026→courtyard 0.022→picnic_area |
0.522→patio 0.041→porch 0.040→restaurant_patio 0.024→courtyard 0.017→zen_garden |
| 地下鉄のホーム (1536×1024) |
0.785→subway_station/platform 0.208→train_station/platform 0.002→arcade 0.001→bus_station/indoor 0.001→jail_cell |
0.736→subway_station/platform 0.228→train_station/platform 0.005→arcade 0.004→locker_room 0.003→bus_station/indoor |
| オフィス (1536×1024) |
0.237→library/indoor 0.119→computer_room 0.108→office_cubicles 0.103→legislative_chamber 0.093→classroom |
0.226→library/indoor 0.189→computer_room 0.130→office_cubicles 0.065→office 0.057→classroom |
| 公園(Formalgarden) (1536×1024) |
0.590→formal_garden 0.342→topiary_garden 0.033→vineyard 0.013→vegetable_garden 0.005→roof_garden |
0.305→formal_garden 0.117→topiary_garden 0.070→greenhouse/indoor 0.056→vegetable_garden 0.035→field/cultivated |
| 芝生の上を歩く猫 (1536×1024) |
0.283→lawn 0.248→rice_paddy 0.091→field/wild 0.082→hayfield 0.058→pasture |
0.214→rice_paddy 0.114→lawn 0.100→aquarium 0.096→underwater/ocean_deep 0.048→field/wild |
表2 試験データと結果(静止画 vs. 動画)2
結果を考察してみます.まず,公園(formal garden)シーンの場合,静止画ではformal_gardenが0.590と優勢でしたが,動画では0.305に低下しました.ただしTop-2までは同じクラスが並び,その他のクラスは0.1以下と低い値にとどまっています.従って,実質的には同様の推論結果と考えてよいでしょう.
次に芝生の上を歩く猫のシーンですが,このシーンでは大きな違いが見られました.動画ではTop-1/Top-2の順位が入れ替わっただけでなく,aquariumやunderwater/ocean_deepといった屋外とは無関係なクラスが上位に出現しました.この静止画(1536×1024)を640×480に縮小して再推定した結果は次の通りで,元の静止画とほぼ同じ分布となりました.
******
0.339 -> lawn
0.266 -> rice_paddy
0.099 -> field/wild
0.064 -> hayfield
0.050 -> pasture
******
従って,単純に解像度を縮小しただけでは動画で見られた誤認は再現されませんでした.このことから,動画推定でaquariumやunderwaterが出現した要因は,フレーム・サイズ変更やエンコード処理の過程で色味や質感が微妙に変化して水槽や水中に近い特徴として解釈された可能性が高いと考えられます.
▲3,モデル:resnet18,画面サイズ:960×720
結果を表3に示します.
| 試験画像(画面サイズ) | 静止画 | 動画 |
|---|---|---|
| 庭(patio) (640×426) |
0.621→patio 0.310→restaurant_patio 0.020→beer_garden 0.011→courtyard 0.011→porch |
0.929→patio 0.039→restaurant_patio 0.008→courtyard 0.007→beer_garden 0.005→porch |
| 地下鉄のホーム (1536×1024) |
0.893→subway_station/platform 0.106→train_station/platform 0.000→arcade 0.000→railroad_track 0.000→corridor |
0.918→subway_station/platform 0.077→train_station/platform 0.001→arcade 0.001→corridor 0.001→alley |
| オフィス (1536×1024) |
0.244→office_cubicles 0.190→computer_room 0.141→office 0.135→library/indoor 0.120→classroom |
0.295→computer_room 0.232→library/indoor 0.104→office_cubicles 0.089→office 0.078→lecture_room |
| 公園(Formalgarden) (1536×1024) |
0.231→botanical_garden 0.224→park 0.211→formal_garden 0.084→orchard 0.077→field/wild |
0.836→formal_garden 0.043→vegetable_garden 0.031→topiary_garden 0.030→botanical_garden 0.015→roof_garden |
| 芝生の上を歩く猫 (1536×1024) |
0.338→field_road 0.271→lawn 0.181→rice_paddy 0.066→pasture 0.047→hayfield |
0.376→lawn 0.209→field_road 0.061→rice_paddy 0.058→pasture 0.038→aquarium |
表3 試験データと結果(静止画 vs. 動画)3
結果を考察してみます.まず,庭(patio),地下鉄のホーム,オフィスのシーンですが,静止画と動画で同じ傾向が見られました.Top-1クラスは一致し,確率値も近い範囲に収まっています.特にオフィスではcomputer_roomやlibrary/indoorがoffice_cubiclesよりも上位に出ましたが,全体的に確率値が低いため,これは近縁クラス間での揺らぎと解釈できます.
次に公園(formal garden)シーンですが,検証1(640×480)の結果と同じように,静止画ではformal_gardenが分散した候補のひとつにとどまりましたが,動画ではformal_gardenが0.836と圧倒的に優勢になりました.解像度を960×720に上げても同じ傾向が確認でき,動画入力時にはformal_gardenが安定的に強調されるといえます.
最後に芝生の上を歩く猫のシーンですが,静止画ではfield_road,lawn,rice_paddyなどが混在していましたが,動画ではlawnが最も高くなり,全体的な分布は近い傾向を示しました.ただし,少数ながらaquariumといった不適切なクラスが再び現れており,動画化やエンコード処理に伴う色味や質感の変化による誤認が依然として残っていることが確認されました.
▲4,モデル:wideresnet18,画面サイズ:960×720
結果を表4に示します.
| 試験画像(画面サイズ) | 静止画 | 動画 |
|---|---|---|
| 庭(patio) (640×426) |
0.651→patio 0.068→restaurant_patio 0.043→porch 0.026→courtyard 0.022→picnic_area |
0.532→patio 0.043→porch 0.042→restaurant_patio 0.024→courtyard 0.016→zen_garden |
| 地下鉄のホーム (1536×1024) |
0.785→subway_station/platform 0.208→train_station/platform 0.002→arcade 0.001→bus_station/indoor 0.001→jail_cell |
0.717→subway_station/platform 0.229→train_station/platform 0.007→arcade 0.006→locker_room 0.005→medina |
| オフィス (1536×1024) |
0.237→library/indoor 0.119→computer_room 0.108→office_cubicles 0.103→legislative_chamber 0.093→classroom |
0.235→library/indoor 0.185→computer_room 0.111→office_cubicles 0.064→office 0.047→classroom |
| 公園(Formalgarden) (1536×1024) |
0.590→formal_garden 0.342→topiary_garden 0.033→vineyard 0.013→vegetable_garden 0.005→roof_garden |
0.325→formal_garden 0.105→topiary_garden 0.058→greenhouse/indoor 0.054→vineyard 0.046→vegetable_garden |
| 芝生の上を歩く猫 (1536×1024) |
0.283→lawn 0.248→rice_paddy 0.091→field/wild 0.082→hayfield 0.058→pasture |
0.144→underwater/ocean_deep 0.118→rice_paddy 0.111→aquarium 0.101→lawn 0.046→pet_shop |
表4 試験データと結果(静止画 vs. 動画)4
結果を考察してみます.まず,庭(patio),地下鉄のホーム,オフィスのシーンですが,静止画と動画で大きな差はなく,Top-1クラスは一致しました.確率値も近い範囲に収まっており,解像度を960×720に上げても安定した結果となりました.
次に公園(formal garden)シーンですが,静止画ではformal_gardenが0.590で優勢でしたが,動画では0.325へ低下しました.ただし,Top-2までは同じクラスが上位を占めており,全体の分布は近似しています.
最後に芝生の上を歩く猫のシーンですが,差異が目立ったのはこのシーンでした.動画ではunderwater/ocean_deep,aquariumなど本来無関係なクラスが上位に出現しました.ただし,静止画/動画いずれでも確率値は全体的に低く,分類が不安定なサンプルであることを示しています.そのため,この違いはもともとの曖昧さが動画処理時に強調された結果と解釈できます.
●推論の基になった要素を表した画像の比較
今回の検証では,同じシーンを静止画と動画で入力した際に,モデルが注目している領域(特徴量の抽出部位)に違いがあることを確認しました.画像比較を表5に静止画/動画の比較結果を表6にそれぞれ示します.
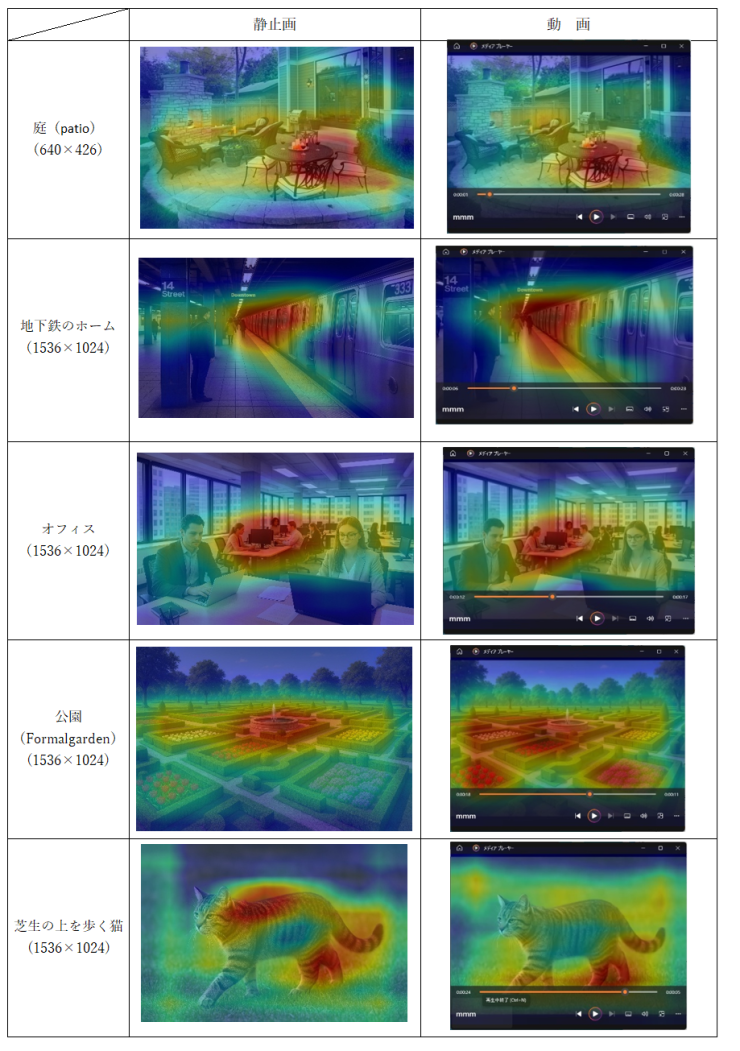
表5 静止画/動画の推定結果比較1(画像)
| シーン | 静止画 | 動画 |
|---|---|---|
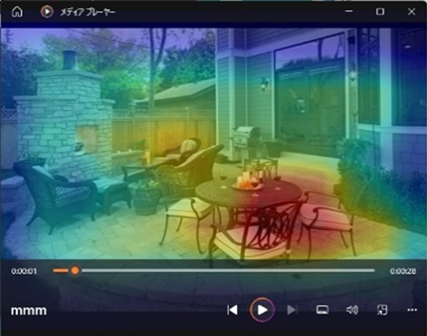
| 庭(patio,640×426) | patio周辺の構造物やテーブル部分を主に注目 | 類似の領域を注目し,結果に大きな差はなし |
| 地下鉄のホーム(1536×1024) | ホーム床面や線路沿いの構造を注目 | 同様に線路沿いを注目し、安定した分類 |
| オフィス(1536×1024) | 机やパーティションの一部に注目 | 類似領域を注目している |
| 公園(formal garden,1536×1024) | 噴水周辺が主な推論対象 | 花畑全体に注目が広がり,formal_garden の確率が上昇 |
| 芝生の上を歩く猫(1536×1024) | 芝生や背景を注目し,猫自体はほぼ無視 | 静止画同様,猫の模様は対象外で,芝生部分の質感が推論の基準に |
表6 静止画/動画の推定結果比較2(特徴)
公園(formal garden)シーンですが,静止画では噴水といった局所的な特徴に依存していましたが,動画では花畑全体を参照する傾向が強まり,formal_gardenの確率が高くなりました.
次に芝生の上を歩く猫のシーンですが,静止画/動画ともに猫の模様は推論対象になっておらず,芝生部分のテクスチャが主な手掛かりとなっていました.そのため,動画では色味や質感の変化が影響し,aquarium,underwaterど不適切なクラスが出現した可能性があります.
静止画と動画では,モデルが注目する領域に差が生じる場合があり,特に公園や芝生の猫のようにシーン内に複数の要素が含まれる場合は,局所特徴と全体特徴のどちらを重視するかで結果が変わることがわかりました.
●処理速度
今回の計測では,プログラム・コードを編集し場所推定処理にかかる時間を計測しました.対象は20秒(約600 フレーム,30fps)の動画で,処理に要した実時間(秒)をまとめたものを表7に示します.
|
画面サイズ 実行環境 |
resnet18 | wideresnet18 | ||
|---|---|---|---|---|
| 640×480 | 960×720 | 640×480 | 960×720 | |
| –env_id=0 | 15.84 | 17.89 | 27.1 | 29.05 |
| –env_id=1 | 16.82 | 18.08 | 24.04 | 29.03 |
| –env_id=2 | 3.92 | 6 | 5.38 | 6.9 |
| –env_id=3 | 3.65 | 5.84 | 4.6 | 6.46 |
表7 処理速度の比較
▲GPUの効果
GPUを利用することで,CPU比で約4倍以上の高速化が得られました.特にFP16実行では最も高速で,20秒の動画を3.6〜6.5秒程度で処理できました.
▲CPUでの実行
ResNet-18であればCPU実行でも20秒以下で処理可能であり,ほぼリアルタイムでの推定が可能であることを確認しました.一方,WideResNet-18は計算量が増えるためCPU実行ではリアルタイム処理が厳しく,GPUの利用が望まれます.
▲解像度の影響
解像度を640×480から960×720に上げると処理時間は1.2〜1.5倍程度に増加しました.ただし GPU実行では増加幅が比較的小さく,解像度向上による恩恵を受けやすい環境といえます.
●まとめ
今回は,ailia-SDKとPlaces365系モデルを用いた動画入力での場所推定を検証しました.静止画と動画の比較,解像度やモデルの違い,さらに処理速度の計測を行った結果,次の知見が得られました.
▲モデルによる特徴
ResNet-18は軽量で,CPUでも20 秒の動画をリアルタイムに近い速度で処理可能でした.また,WideResNet-18は精度向上が期待できるものの,計算量が増加しCPU実行ではリアルタイム性が難しく,GPU環境での利用が望まれます.
▲静止画と動画の違い
多くのシーンでは,静止画と動画で同様の傾向が得られましたが,公園や芝生の猫など複数の特徴を含むシーンでは,動画入力時に注目部位が変化し,推定結果が安定化または誤認に振れるケースが確認されました.特に公園(formal garden) では,静止画が噴水周辺を重視したのに対し,動画では花畑全体を参照し,formal_gardenの確率が大幅に向上するなど,注目領域の違いが推定結果に影響しました.
▲解像度の影響
解像度を640×480から960×720に上げると,一部シーンで確率の分布が変化しましたが,全体的な傾向は大きく変わりませんでした.一方で,処理時間は1.2〜1.5倍程度に増加し,解像度向上は推定精度と処理速度のトレードオフとなることがわかりました.
▲処理速度
GPUを利用することでCPU実行の約4〜5倍の高速化が可能でした.特にRTX 3060 (FP16) では20秒の動画を4〜6秒程度で処理でき,十分なリアルタイム性が得られます.ResNet-18であればCPU実行でもリアルタイム処理が可能であり,環境に応じた柔軟な選択が可能です.
▲使い分けの指針
手軽に動作確認やリアルタイム推定を行いたい場合はResNet-18+CPUで精度を重視し,安定した認識を得たい場合はWideResNet-18+GPUとなります.
▲実務上の注意
動画入力やリサイズによって推定結果が変わる場合があるため,実務で利用する際の注意点について述べます.
まず,一般的なシーン分類モデルと同じように,本サンプル・プログラムでも推論直前に固定サイズへのリサイズ処理が行われます.そのため単なる画面サイズの違いではなく,リサイズやクロップの過程で構図が変化し,推定結果に影響を与える可能性があります.
次に元画像の縦横比や解像度が異なると,スケーリング比率やクロップ位置が変わり,静止画と動画で注目される領域が変化することがあります.
最後に複数の要素を含むシーンでは,モデルが局所的な特徴に依存するのか全体の特徴を重視するのかによって推定結果が変動することがあります.そのため,評価段階では静止画と動画の両方で挙動を確認することが望ましいです.
氏森 充(うじもり・たかし)
約30年間,(株)構造計画研究所にてIoT,ビッグデータ,機械学習,AI関連のシステム開発や実務応用に従事.退職後はLLM(大規模言語モデル)関連の情報収集や技術動向の調査・発信に注力し,雑誌「Interface」でもLLM技術に関する記事を執筆中.








ショップへのリンク")

