


Interface編集部
ailia SDKを試す<第16回> YOLO11を利用したオブジェクト検出のモデル比較(動画編)
今回は,前回紹介した静止画のオブジェクト検出のモデル比較(https://interface.cqpub.co.jp/ailia015/)に続き,YOLO11-segがサポートする複数のモデルを用いて,動画入力におけるオブジェクト検出性能を比較します.主な評価項目としては,各モデルの検出結果(検出精度)と,処理速度(FPSなど)の違いについて検証しました.
●使用するモデル
今回の検証対象のモデルは,
******
・YOLO11n-seg
・YOLO11s-seg
・YOLO11m-seg
・YOLO11l-seg
・YOLO11x-seg
******
の計5種類です.それぞれのモデルの特徴や主な用途については,前回の記事に掲載した表をご参照ください.
なお,今回は環境構築方法などについては扱いません.実行環境のセットアップ方法や基本的な使い方,静止画での動作確認手順については,第13回の記事(https://interface.cqpub.co.jp/ailia013/)をご参照いただければと思います.
●使用する動画や検証方法
前回の静止画検証では,第14回(https://interface.cqpub.co.jp/ailia014/)で使用したものと同じ動画素材を利用しています.
処理速度(FPS)の計測は,30フレーム(1秒分)ごとにかかった時間を測定し,その値を4回(合計4秒分)取得したうえで平均値を算出しています.また,各オブジェクトの検出個数についても,4回分の平均値を記載しています.検出カテゴリの個数が小数となっている場合は,検出数に揺らぎがあったことを意味します.これは,動画のオブジェクト検出において,フレームごとに検出結果が微妙に変動するためです.
なお,画面には30フレーム(1秒分)ごとのFPSが表示されていますが,ここで示す数値は120フレーム(4秒分)の平均値であるため,表示値とは異なる場合があります.また,YOLO11nについては,前回と同じ環境で検証を行っていますが,計測結果が前回の値と若干異なる場合があります.これも動画検出時に生じる揺らぎの1つとご理解ください.
●動画を入力して精度や挙動を検証
▲1,イベント風景
検出結果を図1に示します.
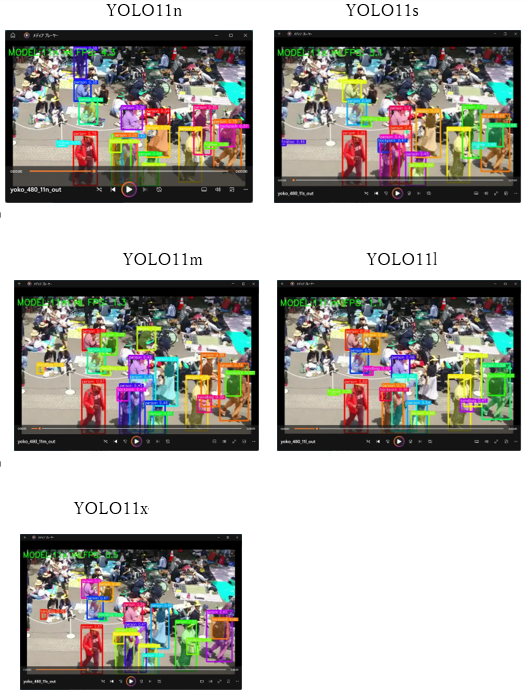
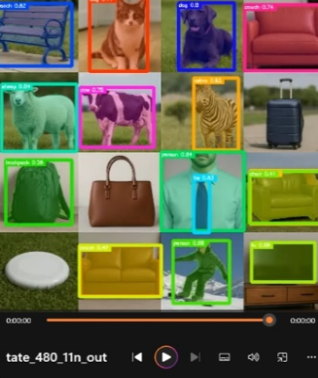
図1 オブジェクト検出結果(イベント風景)
次に,モデルごとの検出件数の比較を表1に示します.
|
モデル
カテゴリ
|
11N | 11S | 11M | 11L | 11X | |
|---|---|---|---|---|---|---|
| backpack | 2 | 2 | 2 | 2 | 2 | |
| frisbee | 1.25 | 2 | 0 | 0.25 | 0 | |
| handbag | 0 | 0.75 | 3 | 2 | 2.75 | |
| person | 15.25 | 12 | 14 | 12 | 11.5 | |
| 合計数 | 18.5 | 16.75 | 19 | 16.25 | 16.25 | |
| FPS | 4.3 | 3.08 | 1.25 | 1.11 | 0.56 | |
表1 各モデルの検出結果(イベント風景)
(検出件数は,4秒間(4回分)の平均値です.小数点以下は,各フレームごとに検出数が変動したことによるものです)
backpackやpersonの検出数は,全モデルで大きな差はありませんでしたが,handbagやfrisbeeはモデルによって大きく変動しています.合計検出数は,YOLO11mで最も多くなり,FPS(フレーム毎秒)は,モデルが大きくなるほど低下しており,YOLO11nが最も高速で,YOLO11xでは0.56FPSと大きく低下しています.また,小物(handbagやfrisbee)の検出にはモデルごとの特徴が現れやすい一方,人物(person)は安定して検出できていることが分かります.
▲2,新幹線ホーム風景
検出結果を図2に示します.

図2 オブジェクト検出結果(新幹線ホーム風景)
次に,モデルごとの検出件数の比較を表2に示します.
|
モデル
カテゴリ
|
11N | 11S | 11M | 11L | 11X | |
|---|---|---|---|---|---|---|
| Backpack | 0 | 1 | 1 | 1 | 1 | |
| Person | 3 | 6.25 | 7 | 6.5 | 7 | |
| Suitcase | 0 | 1 | 2 | 2 | 2 | |
| Train | 1 | 1 | 1 | 1 | 1 | |
| 合計数 | 4 | 9.25 | 11 | 10.5 | 11 | |
| FPS | 8.53 | 3.57 | 1.31 | 1.17 | 0.57 | |
表2 各モデルの検出結果(新幹線ホーム風景)
personは,モデルが大きくなるほど,遠くに写っている小さく不鮮明な人物も検出できるようになり,検出数が増加する傾向が見られます.suitcaseについても同じように,モデルが大きいほど遠方や不鮮明なスーツケースも検出できるため,検出数が増加しています.
backpackはYOLO11nでは検出されませんでしたが,それ以外のモデルでは安定して検出できています.trainは,全てのモデルで安定して検出できており,モデルによる差は見られませんでした.合計検出数は,YOLO11mおよびYOLO11xが最も多い結果となり,FPS(フレーム毎秒)は,モデル・サイズが大きくなるほど低下し,YOLO11nでは8.53FPSと非常に高速ですが,YOLO11xでは0.57FPSまで低下しています.
▲3,複数オブジェクト・リスト(生成AI作成)
検出結果を図3に示します.

図3 オブジェクト検出結果(複数オブジェクト・リスト)
次に,モデルごとの検出件数の比較を表3に示します.
|
モデル
カテゴリ
|
11N | 11S | 11M | 11L | 11X | |
|---|---|---|---|---|---|---|
| airplane | 1 | 1 | 1 | 1 | 1 | |
| backpack | 1 | 1 | 1 | 1 | 1 | |
| bench | 1 | 1 | 1 | 1 | 1 | |
| car | 1 | 1 | 1 | 2 | 3 | |
| cat |
認識
(dog) |
1 | 1 | 1 | 1 | |
| chair | 2 | 2 | 1 | 1 | 1 | |
| counch | 4 | 3 | 3 | 2 | 2 | |
| cow | 1 | 1 | 1 | 1 | 1 | |
| dog | 2 | 1 | 1 | 1 | 1 | |
| fire hydrant | 1 | 1 | 1 | 1 | 1 | |
| frisbee | 0 | 1 | 1 | 1 | 1 | |
| handbag | 0 | 1 | 1 | 1 | 1 | |
| motorcycle | 1 | 1 | 1 | 1 | 1 | |
| parking meter | 1 | 1 | 1 | 1 | 1 | |
| person | 4 | 3 | 3 | 3 | 3 | |
| sheep | 1 | 1 | 1 | 1 | 1 | |
| snowboard | 0 | 1 | 1 | 1 | 1.25 | |
| stop sign | 1 | 1 | 1 | 1 | 1 | |
| suitcase | 0 | 1.75 | 1 | 1 | 1 | |
| tie | 1 | 1 | 1 | 1 | 1 | |
| train | 1 | 1 | 1 | 1 | 1 | |
| tv | 1 | 1 | 1 | 1 | 1 | |
| zebra | 1 | 1 | 1 | 1 | 1 | |
| 合計数 | 26 | 28.75 | 27 | 27 | 28.25 | |
| FPS | 3.967 | 2.394 | 1.107 | 0.98 | 0.49 | |
表3 各モデルの検出結果(複数オブジェクト・リスト)
表3は,各オブジェクトの検出数のみを掲載し,検出数は,4回分の平均値です.小数点以下は,各回で検出数が異なった場合を示します.また,今回の検証用の画像では couchとchairの区別が難しいため,重複して検出しています.ここでは,いずれも正解として扱っています.
各モデルについて考察してみます.
******
・YOLO11n:静止画での結果とほぼ同じように,frisbee,handbag,suitcaseを検出できませんでした.また,catをdogと誤認するケースも見られました.
・YOLO11s:全てのオブジェクトを正しく検出できました.handbagについてはsuitcaseとしても検出されていますが,ログの詳細を見るとhandbagの推定確率(prob)が0.57,suitcaseが0.42となっており,handbagとして優先的に認識されていることが分かります.また,1つのオブジェクトがchairとcouchの両方で検出される重複も確認できましたが,いずれも推定確率は0.50以上となっており,異なるオブジェクトとして扱われているようです.
・YOLO11s/YOLO11m/YOLO11l/YOLO11x:これらのモデルでは,全てのオブジェクトをほぼ正確に検出できました.特に,chairとcouchの重複検出は,モデル・サイズが大きくなるほど減少する傾向が見られました.
・YOLO11lおよびYOLO11x:背景に隠れたcarも検出できており,より高精度な検出が可能であることが確認できました.
******
●まとめ
検出結果については,基本的に静止画の場合と同様の傾向が見られました.各モデルの特徴を以下にまとめます.
▲YOLO11n/YOLO11s
これらのモデルは軽量かつ処理速度が速いため,リアルタイム性が求められるエッジ・デバイスや監視カメラなどに適しています.特にYOLO11nはFPSが高く,人物や大きな物体については十分な精度で検出できますが,小物類や背景に隠れた物体の検出精度にはやや限界があります.
▲YOLO11m
検出精度と処理速度のバランスが良く,人物や小物,遠方のオブジェクトまで幅広く検出できます.一方で,FPSはやや低下します.エッジ用途でも精度重視の場合や,サーバ側での利用にも適しています.
▲YOLO11l/YOLO11x
これらのモデルは高精度な検出ができ,特に背景に隠れたcarや小さなhandbagなども見逃さずに捉えることができます.誤認も少なく,安定性の高い結果が得られました.ただし,モデル・サイズが大きいため処理速度は大幅に低下し,リアルタイム用途には適していません.主にサーバ推論や高精度が求められる産業用途での利用が想定されます.
▲モデル選択の目安
今回の検証結果から,YOLO11 Segmentationを利用する際のモデル選定の指針は次の通りです.
・リアルタイム性/軽量化を重視する場合
YOLO11nやYOLO11sは処理速度が速く,エッジ・デバイスや組み込み用途に適しています.人物や比較的大きな物体を検出したい場合,これらのモデルで十分なケースが多いです.例えば,監視カメラや簡易ロボットなど,リアルタイム処理を最優先したいシーンに最適です.
・精度と速度のバランスを求める場合
YOLO11mは,検出精度と処理速度のバランスに優れており,幅広い用途に対応できます.小物や遠方の物体も比較的高精度で検出できるため,エッジ環境とサーバ環境の両方で使いやすい選択肢となります.リアルタイム性もある程度維持したいが,精度も妥協したくない場合におすすめです.
・高精度が求められる場合
YOLO11lやYOLO11xは,最も高い検出精度を誇ります.背景に隠れた物体や小さなアイテムも見逃さず検出できる一方,処理速度は大きく低下します.そのため,高精度な画像解析やオフライン処理,産業用途のバッチ推論など,実行速度よりも精度を最優先する用途に適しています.サーバやGPU搭載の高性能マシンでの利用が前提となります.
●今後の展開
今回は動画入力における検出性能の比較を行いましたが,YOLO11m以上のモデルでは,今回の検証環境(N100クラスのPC)では処理速度が遅く,実運用には厳しい結果となりました.次回は,GPUを利用できる環境下で,どの程度処理速度が向上するかについて検証を進めていく予定です.
氏森 充(うじもり・たかし)
約30年間,(株)構造計画研究所にてIoT,ビッグデータ,機械学習,AI関連のシステム開発や実務応用に従事.退職後はLLM(大規模言語モデル)関連の情報収集や技術動向の調査・発信に注力し,雑誌「Interface」でもLLM技術に関する記事を執筆中.








ショップへのリンク")

